This repo contains code for UXLA: A Robust Unsupervised Data Augmentation Framework for Zero-Resouce Cross-Lingual NLP.
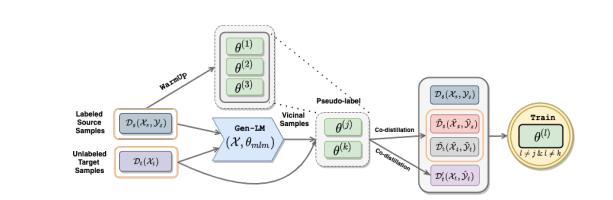
UXLA algorithm mentioned in the paper is trained on multiple stages.
Warmup Stage (Pretraining)
In this stage we train the model with english data only. The best model is selected by the “english development set”. A sample script can be found in in the following address,
scripts/model_scripts/base/base-multilingual_xlmr.sh
LM Augmentation
Now perform data augmentation using XLMR-large language model. You can use the script lm_augmentation.py to do so. A sample script for running lm_augmentation.py is given here,
scripts/lm_augmentation/lm_augmentation.sh
Pseudo Labeling on data
To annotate the augmented data with the pseudo label - follow the sample script here,
Please use the warmup model in place of --model_name_or_path and the respective config at --config_name.
scripts/model_scripts/extract_pseudo_label.sh
Training
Each of the semisupervised epoch is trained through different scipt. Please follow the sample script here,
scripts/multi-mix/*
Please note that the important params of the argument is --aug_desc (describing data mixture), --thetas (pretrained models). The models that are trained in semi-supervised epoch 1, should be used as --thetas for semi-supervised epoch 2. Also make sure that --external_data indicates the necessary LM augmented data.