About
This package includes:
- A discourse segmenter
- A discourse parser
- Evaluation metrics for discourse parsing
Download
Document-level Discourse Parser for English
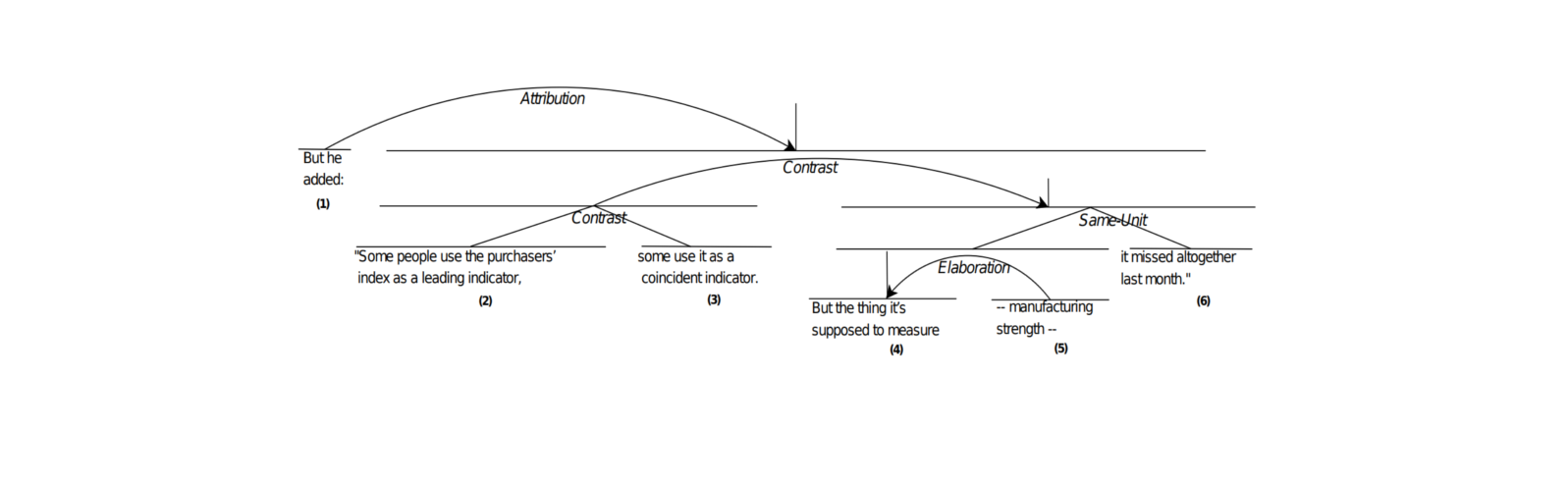
Demo
Installation
Required for the discourse segmenter:
- Charniak’s reranking parser. Put it in Tools/CharniakParserRerank and install it.
- Taggers from UIUC. Download POS tagger and shallow chunker [LBJPOS.jar, LBJChunk.jar, LBJ2.jar, LBJ2Library.jar] and put these in Tools/UIUC_TOOLs/
- Install scikit-learn and scipy (instructions)
- Install java if not installed (instructions for Ubuntu)
- Make sure the Tools/SPADE_UTILS/bin/edubreak is set to executable.
Required for the discourse parser:
- Install wordNet (for example, On ubuntu you can write: apt-get install science-linguistics) and set the WNHOME environment variable to the WordNet directory. WNHOME should contain the dictionary files.
- Install WordNet::QueryData (http://search.cpan.org/dist/WordNet-QueryData/QueryData.pm; also provided). To install it properly you may need to set the
$wnHomeUnixand$wnPrefixUnixto the appropriate directories.
Usage
For parsing a raw text, you should run discourse segmenter followed by discourse parser.
Running the discourse segmenter:
$ python Discourse_Segmenter.py
Running the discourse parser:
$ python Discourse_Parser.py
Download
Evaluation Metrics for Discourse Parsing. Latest release. Implementation of the standard evaluation metrics as described in Dan Marcu’s book.
Usage
- Extract Set.tar.gz.
Run the perl script:
Perl ParsingAccuracyMeasuresDocLevelForSystems.pl path_to_sys_dir path_to_gold_dir res.out
The main perl script takes three arguments:
Path to the directory with the system annotations: The filenames should end with *. doc_dis, but you can change the code according to your need. Here is where you need to change:
my @canFiles = grep /\w+\.doc_dis/, readdir(DIR);Path to the Directory with the gold annotations: It assumes that the file names are the same as the system outputs (e.g., *.doc_dis).
The name of the output file: In the output file, it shows the results for the individual documents as well as the summary.
A sample output file is attached. The parsed documents should have the same format as RST-DT.
Related publications
Shafiq Joty, Giuseppe Carenini, and Raymond Ng. 2015. CODRA: A Novel Discriminative Framework for Rhetorical Analysis. Computational Linguistics, Volume 41:3, MIT Press. [Link to PDF]
@article{joty-carenini-ng-cl-15,
title="{CODRA: A Novel Discriminative Framework for Rhetorical Analysis}",
author={Joty, Shafiq and Carenini, Giuseppe and Ng, Raymond T},
journal = {Computational Linguistics},
volume={41:3},
publisher={MIT Press},
pages={385-435},
year={2015},
}
Shafiq Joty, Giuseppe Carenini, Raymond Ng and Yashar Mehdad. Combining Intra- and Multi-sentential Rhetorical Parsing for Document-level Discourse Analysis. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL 2013), Sofia, Bulgaria. [Link to PDF]
@inproceedings{joty-carenini-ng-mehdad-acl-13,
Title = {Combining Intra- and Multi-sentential Rhetorical Parsing for Document-level Discourse Analysis},
Author = {Joty, Shafiq and Carenini, Giuseppe and Ng, Raymond T. and Mehdad, Yashar},
Address = {Sofia, Bulgaria},
Booktitle = {Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics},
Numpages = {9},
Publisher = {ACL},
Series = {ACL-13},
pages = {486-496},
Year = {2013},
}
Shafiq Joty, Giuseppe Carenini and Raymond Ng. A Novel Discriminative Framework for Sentence-Level Discourse Analysis. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the Conference on Natural Language Learning (EMNLP-CoNLL 2012), Jeju, Korea. [PDF]
@inproceedings{joty2012novel,
title={A novel discriminative framework for sentence-level discourse analysis},
author={Joty, Shafiq and Carenini, Giuseppe and Ng, Raymond T},
booktitle={Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning},
Series = {EMNLP-CoNLL-12},
pages={904-915},
year={2012},
organization={Association for Computational Linguistics}
}
License
The Discourse Parser is an Open Source Software, and is released under the Common Public License. You are welcome to use the code under the terms of the licence for research purposes ONLY, however please acknowledge its use with a citation given above in the Related publications.