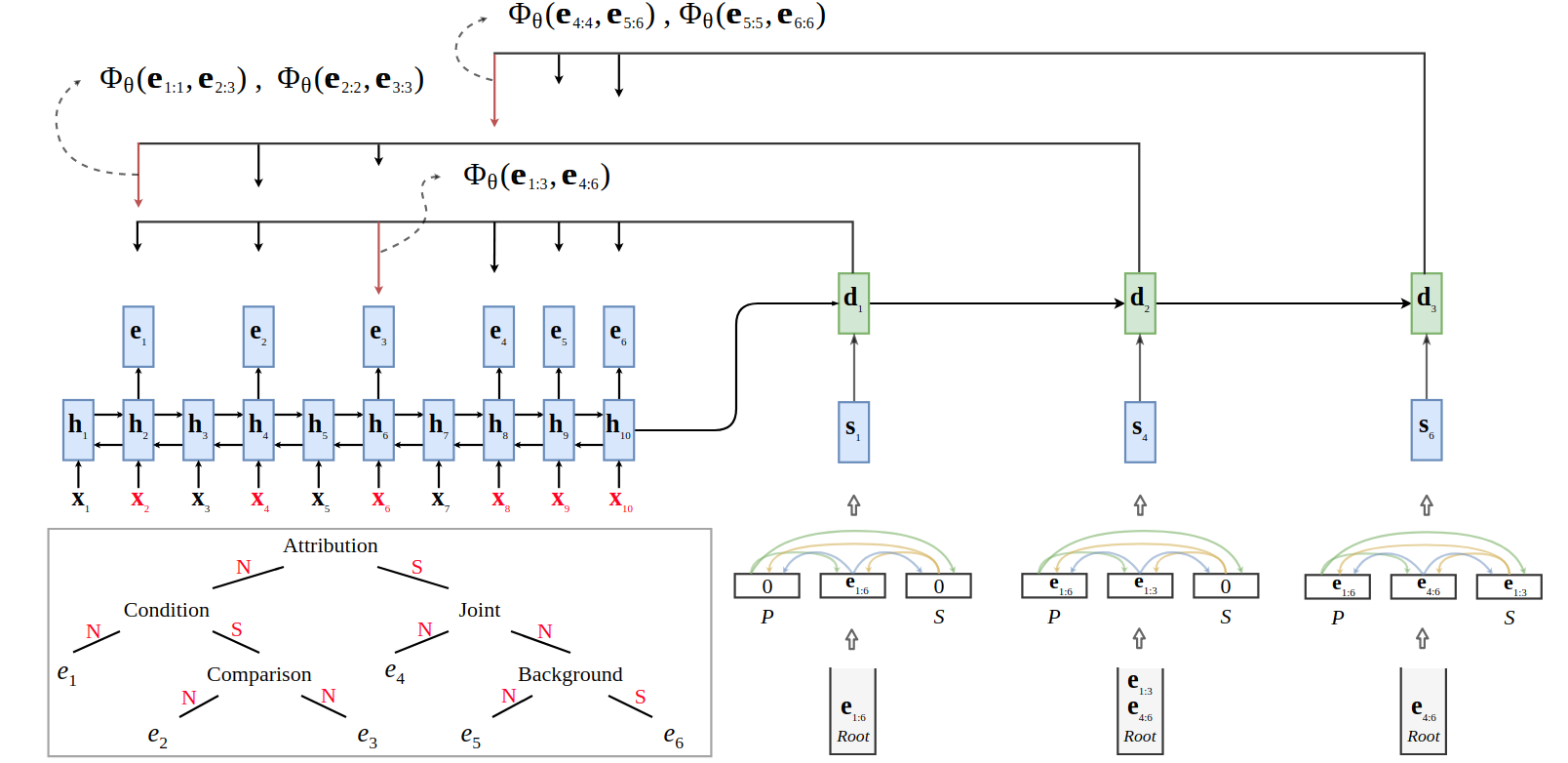
This repository contains the source code of our paper “A Unified Linear-Time Framework for Sentence-Level Discourse Parsing” in ACL 2019.
Getting Started
These instructions will help you to run our unified discourse parser based on RST dataset.
Prerequisites
* PyTorch 0.4 or higher
* Python 3
* AllenNLP
Dataset
We train and evaluate the model with the standard RST Discourse Treebank (RST-DT) corpus. * Segmenter: we utilize all 7673 sentences for training and 991 sentences for testing. * Parser: we extract sentence-level DTs from a document-level DT by finding the subtrees that span over the respective sentences. This gives 7321 sentence-level DTs for training, 951 for testing, and 1114 for getting hu- man agreements.
Data format
Example
Sentence: (Input sentences should be tokenizaed first. ‘[]’ denotes the EDU boundary tokens.)- Although the [report,] which has [released] before the stock market [opened,] didn’t trigger the 190.58 point drop in the Dow Jones Industrial [Average,] analysts [said] it did play a role in the market’s [decline.]
- Although the [report,] which has [released] before the stock market [opened,] didn’t trigger the 190.58 point drop in the Dow Jones Industrial [Average,] analysts [said] it did play a role in the market’s [decline.]
EDU_Breaks: (The indexes of the EDU boundary words, including the last word of the sentence.)- [2, 5, 10, 22, 24, 33]
- [2, 5, 10, 22, 24, 33]
Gold Discourse Tree structure: (The output of the parser also holds for the format.)- (1:Satellite=Contrast:4,5:Nucleus=span:6) (1:Nucleus=Same-Unit:3,4:Nucleus=Same-Unite:4) (5:Satellite=Attribution:5,6:Nucleus=span:6) (1:Satellite=span:1,2:Nucleus=Elaboration:3) (2:Nucleus=span:2,3:Satellite=Temporal:3)
- (1:Satellite=Contrast:4,5:Nucleus=span:6) (1:Nucleus=Same-Unit:3,4:Nucleus=Same-Unite:4) (5:Satellite=Attribution:5,6:Nucleus=span:6) (1:Satellite=span:1,2:Nucleus=Elaboration:3) (2:Nucleus=span:2,3:Satellite=Temporal:3)
Parsing_Label(This should accord with Top-Down Depth-First manner. e.g., There are 6 EDUs in this case. At the first decoding step, the parser will predict 4th (index 3) EDU as the break position such that two new splits (EDU1-EDU4 and EDU5-EDU6) are generated.- [3, 2, 0, 1, 4]
- [3, 2, 0, 1, 4]
Relation_Label(In all we have 39 relations in our model. Each time two newly splits are created, the classifier would predict the corresponding relation label between them.)- [3, 17, 5, 30, 21]
- [3, 17, 5, 30, 21]
For training, you will need to prepare
decoder_input_indexas the decoder input and correspondingparent_index,sibling_indexas the partial tree information.- decoder_input_index: [ 0 , 0 , 0 , 1 , 4 ] - to take the first EDU as the representation of text span to be parsed. or [ 5 , 3 , 2 , 2 , 5 ] - to take the last EDU as the representation of text span to be parsed.
- parent_index: [ 0 , 5 , 4 , 3 , 6 ]
- sibling_index: [ 99 , 99 , 99 , 0 , 4 ] - ‘99’ denotes empty siblings.
How To Run
Parser:
cd Parser/ python train.pyYou can also control any other arguments. Please refer to
main.py. By default, the parser will use the same parameters as described in the paper.Segmenter:
To be released..
Citation
Please cite our paper if you found the resources in this repository useful.
@inproceedings{Xiang19,
Address = {Florence, Italy},
Author = {Xiang Lin and Shafiq Joty and Prathyusha Jwalapuram and M Saiful Bari},
Booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
Numpages = {9},
Publisher = {ACL},
Series = {ACL '19},
pages = {xx--xx},
Title = {{A Unified Linear-Time Framework for Sentence-Level Discourse Parsing}},
Year = {2019},
url = {https://arxiv.org/abs/1905.05682}
}